Project
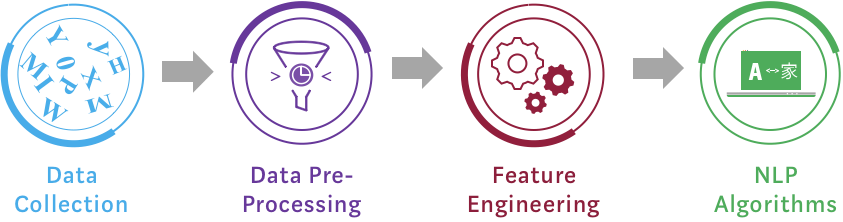
With the data pipeline below to collect, pre-process, feature-engineer, NLP alogorithm applied to provide useful dashboard for analysis and further actions.
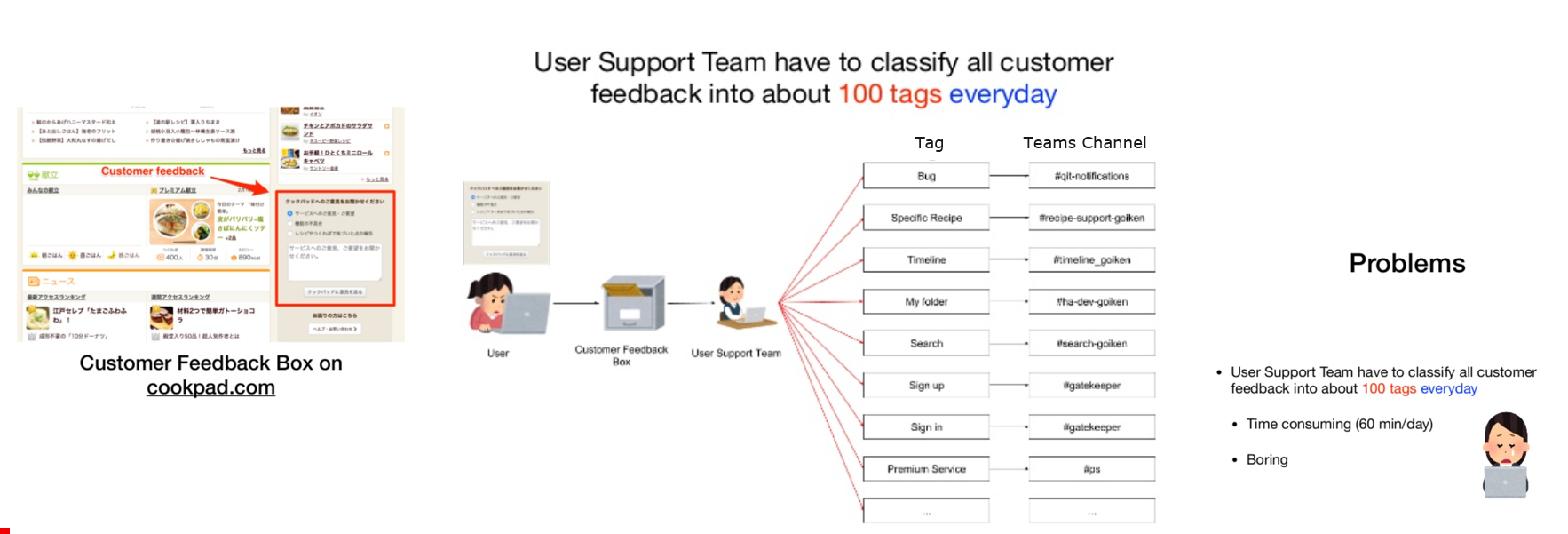
Steps
Data Collection:
Data mining or ETL (extract-transform-load) process to collect a corpus of unstructured data.
Data Preprocessing:




-
Tokenization: Segmentation of running text into words.
-
Lemmatization: Removal of inflectional endings to return the base form.
-
Parts-of-speech tagging: Identification of words as nouns, verbs, adjectives etc.
-
Lanaguage detection: Identification of the lanauges from single or several sentensces even a short one.
Feature Engineering (NLP visualization):
-
Word Embeddings: Transforming text into a meaningful vector or array of numbers.
-
N-grams: An unigram is a set of individual words within a document; bi-gram is a set of 2 adjacent words within a document.
-
TF-IDF values: Term-Frequency-Inverse-Document-Frequency is a numerical statistic representing how important a word is to a document within a collection of documents.
Application of NLP Algorithms:
-
Latent Dirichlet Allocation: Topic modeling algorithm for detecting abstract themes from a collection of documents.
-
Support Vector Machine: Classification algorithm for detection of underlying consumer sentiment.
-
Long Short-Term Memory Network: Type of recurrent neural networks for machine translation used in Google Translate.
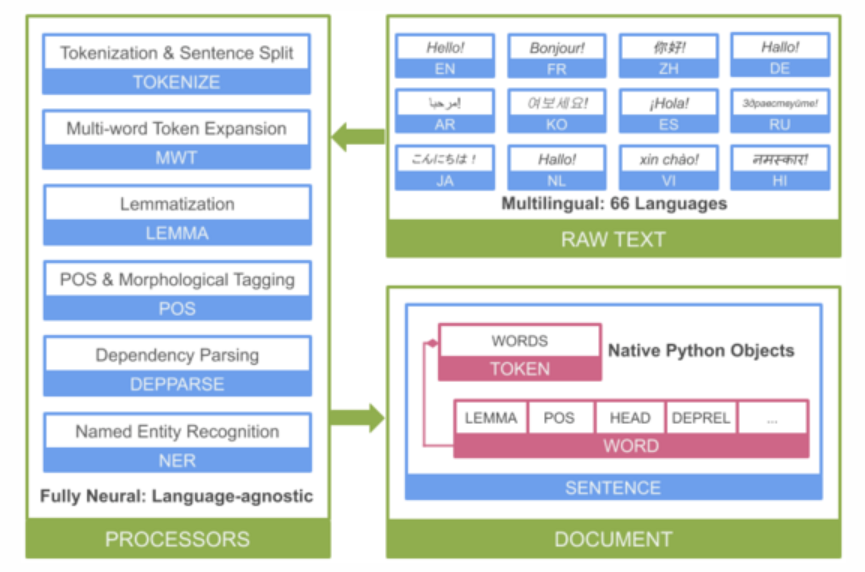
Scope
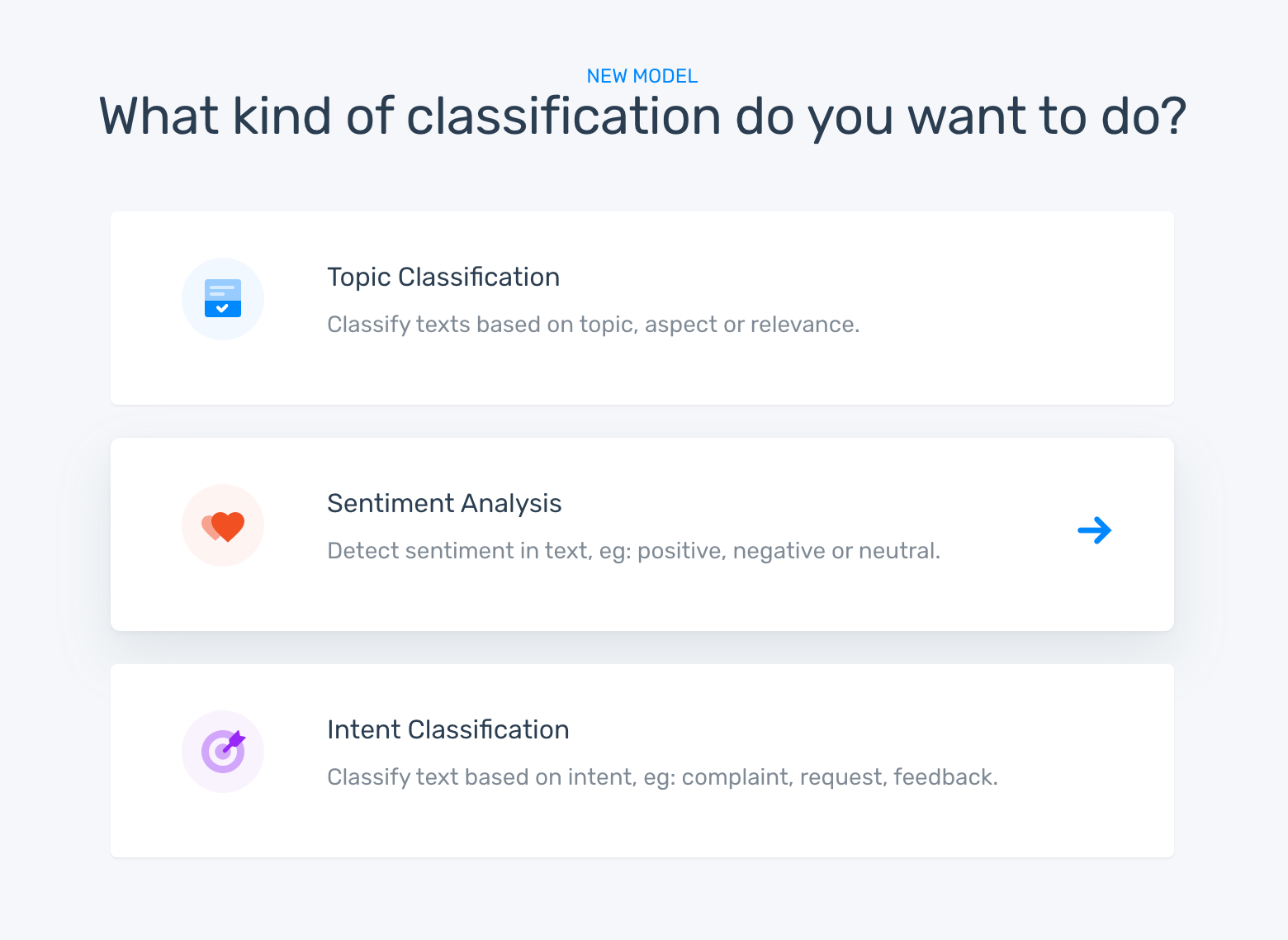
- Topic Modeling: How to automatically categorize customer complaints or intent classification?
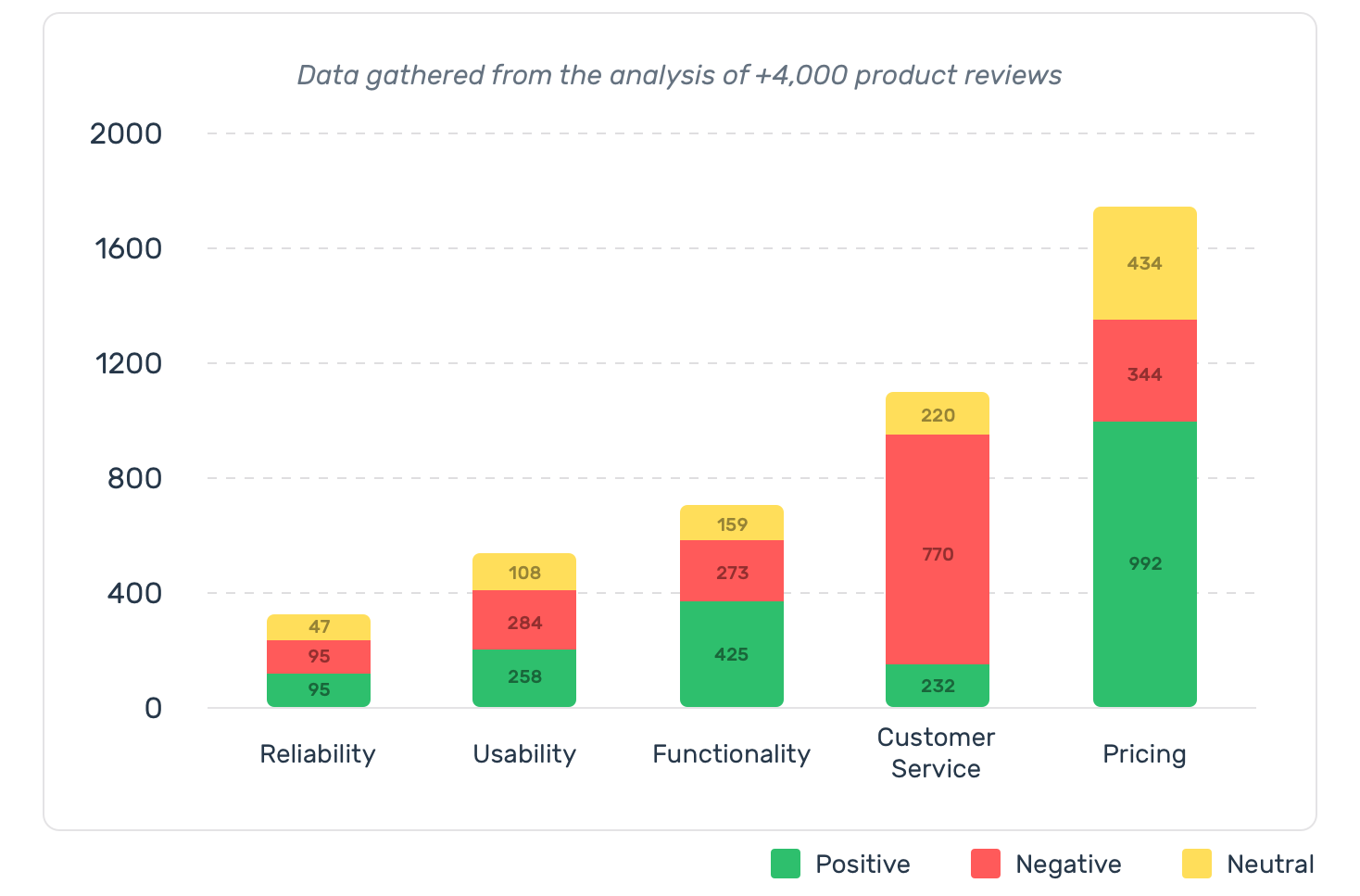

- Sentiment analysis
- How to detect sentiment from customer feedback, a complaint or a positive feedback?
- How to detect urgency?
Implementation: WinkNLP
Customize tagging keyword
Implementation: spaCy
Customize tagging keyword
A high level view of generic model and the refine model in the whole process.
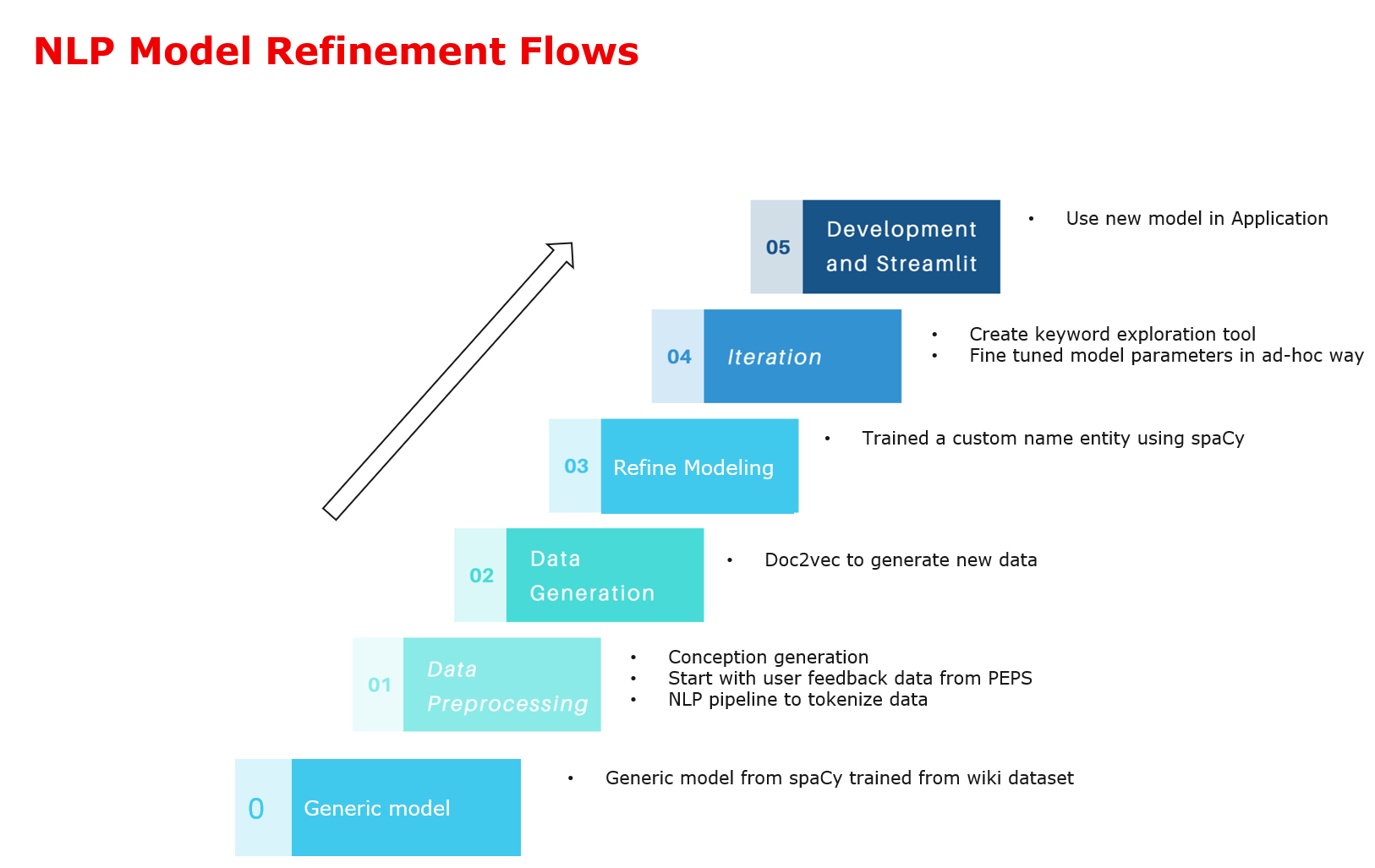
The detailed NLP refinement model is as below to improve the models of NER Tagging in spaCy model on user feedback.
Another better idea is Active learning as below
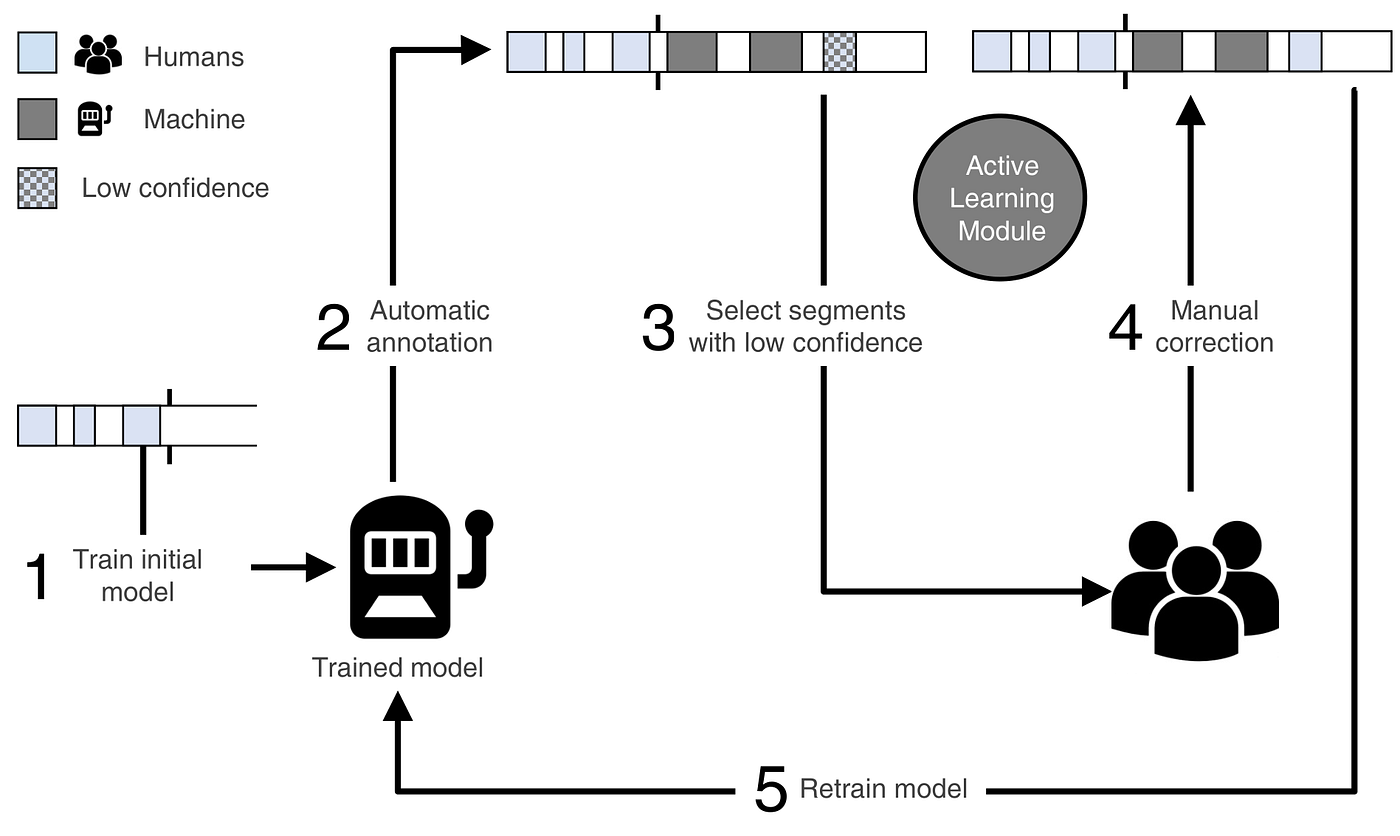
and the whole data pipeline diagram for user feedback tagging is as below
References
- MonkeyLearn: How to Do Customer Complaint Classification with AI
- Humanizing Customer Complaints using NLP Algorithms
- Twitter Sentiment Analysis: A tale of Stream Processing
- 9 Practical Tips for an Effective NPS Data Analysis and Reporting
- The right survey to measure each touchpoint of the customer journey
- Measuring Customer Experience Beyond NPS
- NLP visualizations for clear, immediate insights into text data and outputs
- Predicting happiness: user interactions and sentiment analysis in an online travel forum
- Analyzing Customer reviews using text mining to predict their behaviour
- Awesome Sentiment Analysis
- 10 Popular Datasets For Sentiment Analysis
- 中文情感分析 (Sentiment Analysis) 的难点在哪?现在做得比较好的有哪几家?
- Social Media Data for Sentiment Analysis
- Complete Guide: How to use Grafana with a custom Node API
- NATURAL LANGUAGE PROCESSINGNew AI Detects Sarcasm in Social Media
- Hubspot vs. Marketo: A Side-by-Side Comparison
- What Is Marketo? A Marketer’s Guide
- Amplitude Recommend- Marketo / Amplitude Integration
- 何謂精準行銷 Precision Marketing?精準行銷思維進化史!
- NLP for Beginners: Cleaning & Preprocessing Text Data
- Tutorial: Cleaning CSV Data Using the Command Line and csvkit
- csvkit: a Swiss Army Knife for CSV Data ?
- csvtk - A cross-platform, efficient and practical CSV/TSV toolkit
- Build better products and make better decisions with Iterate.
- How to Motivate Beta Testers to Give You Regular Product Feedback
- Chapter-2 AI Based Next best offer (Behaviour Driven Marketing and CDP)
- Benchmarking Language Detection for NLP
- A Complete Guide to Natural Language Processing (NLP)
- spaCy- Language Processing Pipelines
- How to Use AI in Excel for Automated Text Analysis
- The Complete Guide to Building a Chatbot with Deep Learning From Scratch
- 進入 NLP 世界的最佳橋樑:寫給所有人的自然語言處理與深度學習入門指南
- What are the Limitations of Automatic Image Annotation vs Manual?
- Cohort Analysis: An Insider Look at Your Customer’s Behavior
- Amplitude Recommend- Analyze your predictive cohort
- Customer cohort analysis: Using event data to understand customer behavior
- Customer Cohort Analysis vs User Cohort Analysis: What’s The Difference?
spaCy NER
- How to create training data for spaCy NER models using ipywidgets
- Training Spacy NER models with doccano
- NLP: Named Entity Recognition (NER) with Spacy and Python
- Prepare training data and train custom NER using Spacy Python
- Using spaCy 3.0 to build a custom NER model
- Extend Named Entity Recogniser (NER) to label new entities with spaCy
- How to Train NER with Custom training data using spaCy
- Building a custom Named Entity Recognition model using SpaCy
- tecoholic/ner-annotator Github
NLP Kits
- wink-js- GitHub
- nltk/nltk: NLTK Source - GitHub
- flairNLP/flair: A very simple framework for state-of-the-art Natural Language Processing (NLP)- GitHub
- Industrial Strength NLP- GitHub
- Tools for named entity recognition
- Introducing spaCy v3.0
- spaCy 3.0 demo
Label Annotation
- The 5 Best Data Annotation Platforms & Tools for Machine Learning (2021)
- heartexlabs/awesome-data-labeling- Github
- doccano/awesome-annotation-tools- Github
 Tensorflow.js POC #13: Avatar Generator with Face-API.js
Tensorflow.js POC #13: Avatar Generator with Face-API.js