
| Git Repo | Status | Progress | Comments |
|---|---|---|---|
 |
Pytorch POC #2 | ||
 |
Pytorch POC #3 | ||
 |
Pytorch POC #4 |
Based on last time keyword spotting topics on Chimay, I even mention items about TTS (text-to-speech) and showed POCs. Here I adopt Opentts to create a API server for speech and later ultrasound generation from Web.

In live opentts demo site, you can check the conventional (non-deep learning) speech synthesis (marytts, nanotts) and deep-learning ones (Mozillatts with Tacotron and Tacotron2). Deep-learing ones provide a beeter speech quality. A public MOS test results as below also show similar conclusions.

Demo wave file as
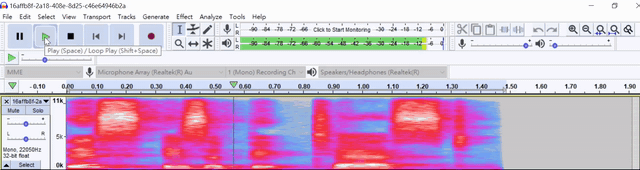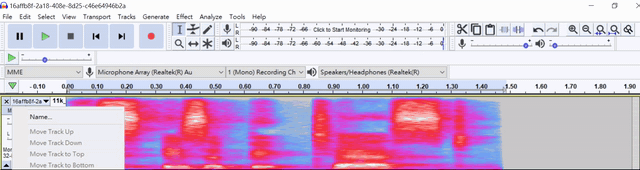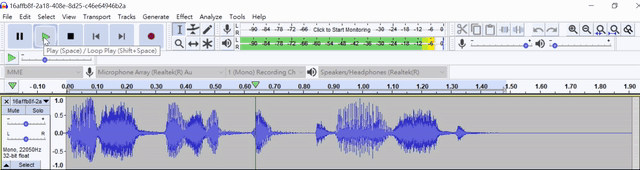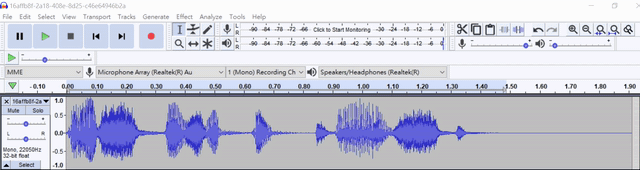
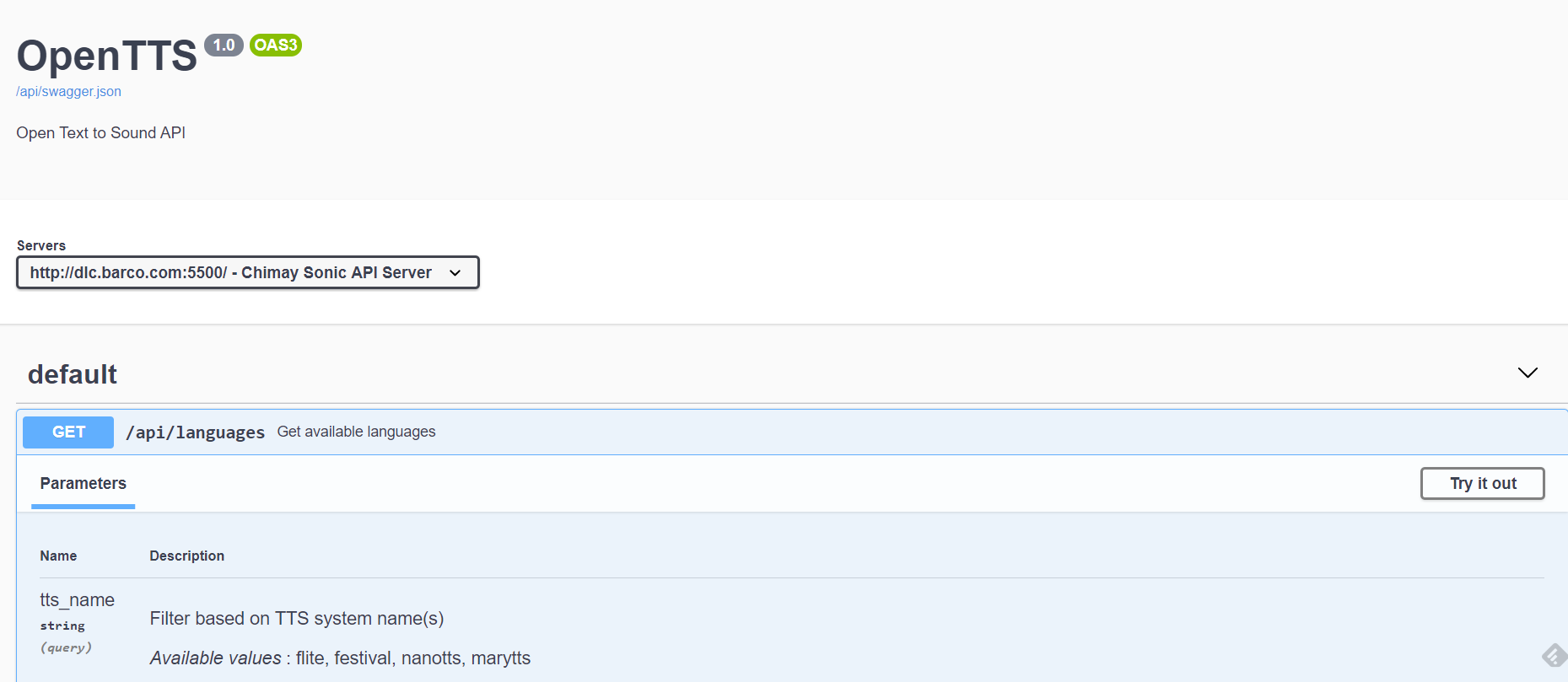
Swagger API also includes the following:
The following diagram is from mozzila project. It shows the whole picture of nature lanaugege iteration with end users. But, of course, it will be a long way to go.

References
- Chimay Architecture for Keyword spotting
- Paper with code- speech synthesis
- Diagram of mozillatts- Tacotron and Tacotron2
- TSS systems and models
- How to build a voice assistant with open source Rasa and Mozilla tools
- The CMU Pronouncing Dictionary
- Build End-To-End TTS Tacotron: Griffin Lim 信号估计算法
- Mozilla 研究:有些機器合成語音已經比真人聲音更悅耳
 Data Trasmit Over Sound- Chimay Ultrasound
Data Trasmit Over Sound- Chimay Ultrasound